High-Range IQ Tests
What Are HRTs
High-range IQ tests (HRTs) are tests that claim to measure IQs of over 160 SD 15, and often IQs above 190. Most are untimed, fluid reasoning tests made by amateur authors.
They can be fun puzzle challenges if you enjoy that sort of thing-but do not rely on them for a solid measure of your FSIQ. A few (e.g., SLSE 1 and SLSE 48 by a qualified psychologist) may be somewhat better. Others by authors like Theodosis Prousalis, Robert Lato, Paul Cooijmans, or Ivan Ivec can be interesting to attempt. However, none approach the norming quality or validated g-loading of mainstream standardized tests (Old SAT, Old GRE, WAIS, etc.).
Criticisms
Recycled logic
Many of these tests spam the same patterns constantly and are highly susceptible to the practice effect.
Ambiguity
Many of the tests have artificially inflated ceilings because nobody can get close to answering all of the questions correctly since they are all ambiguous. You might have some sequence like 2, 4,? Well, this is ambiguous because 6, 8, or 16 are equally valid answers. Of course, this is an HRT measuring up to 210 IQ, so the actual answer will be more like 72389.
Author-specific preferences
A lot of the way to resolve the issue of ambiguity is figuring out the test maker's specific idiosyncrasies and logical preferences. This, of course, provides an advantage to people who have already taken a lot of tests by a particular author or who are willing to invest a lot of time into recognizing these patterns.
Effort
If you do not put in many hours into these tests, you will do worse than someone who does and has your same IQ. You might be 150 IQ, but only invest 2 hours and score 140. Meanwhile, some other 150 IQ dude might put in 50 hours and score 170.
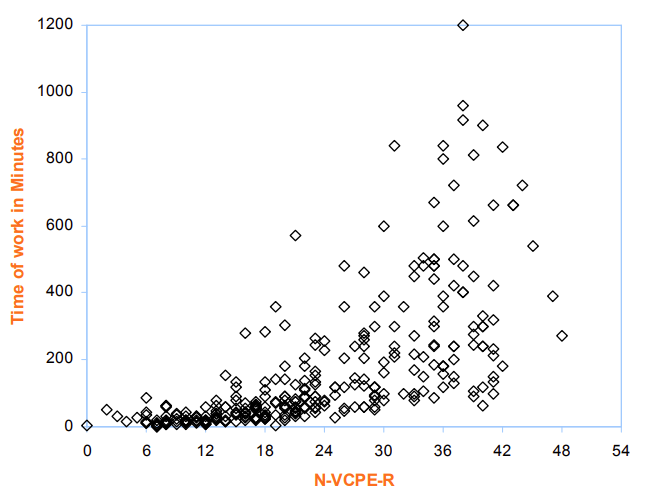
N-VCPE-R: Time of work1
Additionally, there is an interview2 where a famous "high IQ" person claims he has had to spend 150-180 hours on HRTs to achieve his famous 190+ scores and that his original childhood WISC score was 140.
Lack of qualifications
Many of these tests are produced by individuals who do not hold degrees in psychology or even have a basic understanding of statistics or psychometrics, resulting in fundamentally flawed norming and data analysis.
Narrow abilities
A lot of these tests focus on a singular ability or two, such as number series, associations, analogies, or visuospatial induction. This makes them poor at measuring anything other than that particular ability, which is usually a narrow subset of FRI and meaningless for computing an FSIQ. Sometimes a 120 gets 160s on number series tests, and sometimes a 160 gets 120s. Additionally, a lot of these tests really seem to be measuring how much you care and are interested in/willing to invest time in solving a particular puzzle. While being more intelligent will always help, it is not the only large predictive factor at play, making these tests very poor measures of g.
Norms
These tests have many issues with norming.
- Cheating risk: Because administrations are untimed and unsupervised, examinees can consult external resources, artificially inflating raw scores. Honest participants are then normed against a distorted distribution.
- Self-selection bias: Scoring typically requires a fee, so only those confident they performed well are likely to submit their answers. Individuals who feel they scored "average" often withhold their attempt, skewing the normative sample toward outliers and exaggerating percentile conversions.
- Small, unrepresentative samples: Norms are sometimes based on fewer than 30 respondents drawn from online high-IQ forums-hardly reflective of the broader population (or even of the broader high-ability population). Such limited data make any tail-end extrapolation highly unstable.
- Questionable statistical modeling: Developers often apply simple z-score transformations under the assumption of a normal distribution. Yet cognitive ability may deviate from normality in the extreme right tail, and with so few data points a single additional correct item can shift an estimated IQ from 170 to 190-implausibly redefining a difference between "one in a million" and "one in a billion".
Lack of data
High-range tests currently lack any evidence establishing their g-loading or predictive validity. Reported correlations with established tests such as WAIS, SB, AGCT, SAT/GRE etc. usually very poor and derived from small, self-selected samples, giving developers considerable leeway in choosing norms and potentially overstating the strength of any observed relationships.
Taking a look at the Mega Test
Background
The Mega Test, devised by amateur psychometrician Ronald K. Hoeflin3 and first published in Omni magazine in 1985, is perhaps the most infamous "high-range" IQ test. It was an untimed and self-administered test, intended to discriminate among individuals already scoring at the extreme right tail of IQ.
It contains 48 multiple-choice items divided equally between verbal‐analogical and quantitative-spatial problems, and examinees typically worked on the test for several hours before mailing in their answer sheets for scoring. Original norms were derived from fewer than 400 self-selected entrants-mostly enthusiasts from high-IQ circles-with a raw score of 24 anchored to IQ 155.
Although Mega Test results are still recognized by a handful of high IQ societies, the test is no longer actively administered, and its small, non-representative sample means its reliability, g-loading, and predictive validity have never been demonstrated in peer-reviewed research. Its notoriety (and the issues that surround it) makes the Mega Test a prime case study in the pitfalls that plague many HRTs.
Norming & Sample Bias
Before the Mega Test ever reached the public, Omni magazine4 had it "administered to more than 150 people - all members of the major high-IQ societies" simply to show that Mega-society members outscored Prometheus and Triple Nine members. No average ability subjects were included, so the bottom of the scale was never anchored.
According to creator Ronald Hoeflin, "a bit over 4,000 people tried the Mega Test within a couple of years of its appearance."5 He then "look[ed] at the previous test scores that participants reported and tried to create a distribution curve" that would "jibe" with the new raw scores with those earlier, self-reported results. In other words, the Mega Test's norms were built by recycling the same self reported claims about SAT, WAIS, etc.
Hoeflin also "standardized the test six times, using equipercentile equating with SAT and other scores," and he then extended the curve by extrapolation at the far end. Each renorm reused the same data, losing any statistical independence and making the norms increasingly speculative each time. Furthermore, since Mega Test scores are cross-equated to self-reported scores from the same people, external correlations are inflated and the already meager correlations are overstated.
The Mega Test's norms rest on a statistical house of cards built from a narrow sample and further multiplied through rounds of self-referencial norming.
Reliability & Validity
Unlike professional IQ tests that report Cronbach's alpha or split-half figures, the Mega Test has never released internal consistency or test-retest data. With only 48 items (half of them verbal analogies), each raw point carries huge weight, so random guessing or a single lucky insight can shift a possible score by 5 to 10 points.
Furthermore, the test is taken at home with no time limit and with dictionaries, calculators, or other resources. This makes scores more likely to measure time-spent and resourcefulness rather than g and would also be impossible to replicate under controlled conditions. Because solutions are also circulating online, even the Mega Society stopped accepting results after 1994, acknowledging the test was "compromised."6
Correlations between the Mega Test and Other Tests7
| Test | r with Mega | N |
|---|---|---|
| LAIT (Langdon Adult Intelligence Test) | 0.673 | 76 |
| GRE (Graduate Record Examination) | 0.574 | 106 |
| AGCT (Army General Classification Test) | 0.565 | 28 |
| Cattell | 0.562 | 80 |
| SAT (Scholastic Aptitude Test) | 0.495 | 220 |
| MAT (Miller Analogies Test) | 0.393 | 28 |
| Stanford-Binet | 0.374 | 46 |
| CTMM (California Test of Mental Maturity) | 0.307 | 75 |
| WAIS (Wechsler Adult Intelligence Scale) | 0.137 | 34 |
Where correlations have been published, they are weak. In an analysis of Omni-sample data, Mega scores correlated just 0.137 with the WAIS and 0.374 with the Stanford–Binet, well below the ≥0.6 that psychometric guidelines view as "adequate" convergent validity8. What does this mean? The Mega Test is not measuring the same 'g' that IQ tests are aiming to measure, rather, the test appears to capture a narrower set of puzzle-solving skills or test-specific strategies.
Statistical Inflation
Across the six renormings, the Mega Test's ceiling has been stretched far beyond what its data can justify. As mentioned before, due to the circular renorming with self-reported scores from self-selected participants, each renorm pushed the ceiling higher while adding no new information about the general population.
In the original sample of 3,258 takers, only 21 people scored higher than 40. A percentile rank is simply the proportion of the sample that a given score beats. The standard error of that proportion is roughly ≈ 0.14% points, a huge sampling error when you're claiming a rarity of 0.0001%.
The sample for the Mega Test were mostly members or applicants of Triple Nine, Prometheus, etc. Let's suppose that these societies require roughly the top 0.1% on a mainstream IQ test (145+ IQ). Drawing 3,258 such people is like sampling ≈ 3.3 million from the general population. However, even after that generous inflation of the effective population size (and assumptions about the high IQ society's populations), you still expect only 3.3 million * (1/1,000,000) ≈ 3 genuine 1-in-a-million individuals in the whole data set, not multiple at each of several top raw scores. Yet the Mega Test places multiple people at each raw score, inflating rarity by three to four orders of magnitude. Move one answer from wrong to right and you jump multiple percentile slots, not because it's measuring any latent trait, but rather the scale is so coarse.
A 2020 analysis of the same dataset found that "the designer's most recent norming of the Mega Test is too high by six IQ points at a raw score of 10, five IQ points at a raw score of 20, ten IQ points at a raw score of 30 and eleven IQ points at a raw score of 40"9 as well.
Conclusion
The Mega Test's allure is an understandable one, venturing out to measure "genius" that conventional IQ tests supposedly cannot. Yet when its design, sampling, norming, and validation are placed under the same rigorous standards applied to mainstream psychometrics, it does not hold.
Until an HRT meets these standards, its scores should be viewed as puzzle-contest results, not psychometric measurements. Enjoy the challenge of the test by all means, but heavy caution to those who interpret the scores as a measure of g and compareable to other IQ scores.
Citations
Footnotes
-
https://web.archive.org/web/20040405105745/http://www.jouvetesting.org/eng/reports/000300040001.pdf ↩
-
https://in-sightpublishing.com/2024/08/20/rick-rosner-on-his-iq-test-journey/ ↩
-
https://www.docdroid.net/DvwMtpk/megatest-april-1985-omni-mag-pdf ↩
-
http://miyaguchi.4sigma.org/hoeflin/megadata/megacorr.html ↩
-
https://www.researchgate.net/publication/341032783_Do_the_Mega_and_Titan_Tests_Yield_Accurate_Results_An_Investigation_into_Two_Experimental_Intelligence_Tests ↩
-
https://www.mdpi.com/2624-8611/2/2/10/pdf?version=1589360787 ↩