
Word Rarity to IQ Calculator
Enter any English word to find the IQ at which a person has a 50% chance of knowing it.
Word Rarity to IQ Calculator
Enter a word and click Calculate.
| Metric | Value |
|---|---|
| IQ | — |
| 95% CI | — |
| Percentile | — |
How to interpret the result
The IQ shown is the estimated IQ at which a person has a 50% probability of knowing the word. Someone with a higher IQ than the result is more likely to know it; someone with a lower IQ is less likely to know it. Knowing or not knowing a word does not definitively prove any particular IQ, it is probabilistic.
How the calculator works
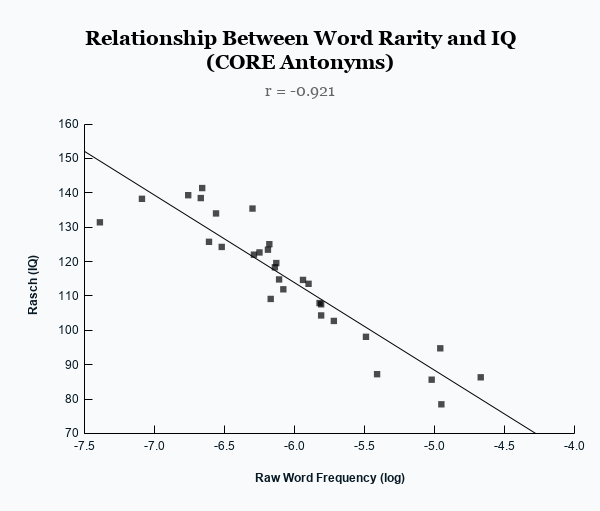
Word frequencies are sourced from a word frequency library. Each word's frequency is expressed as a percentage of all words in the corpus. This calculator uses a word's rarity to predict an IQ score based on the empirical observation that word rarity correlates with the Rasch item difficulty parameter (b) at r = -0.921.
The difficulty parameter b in the Rasch model represents the ability level at which the probability of a correct response is 50%, making word rarity a natural predictor of vocabulary across the IQ distribution.
Limitations
The result reflects VCI specifically, not full-scale IQ. This calculator is made for educational purposes and is not intended as a definitive cognitive assessment.
The model is calibrated on content words (nouns, verbs, adjectives) and breaks down for function words such as the, and, or of (these are known universally regardless of IQ).
It also produces unreliable estimates for words whose spoken frequency diverges sharply from written frequency, such as slang, slurs, or other words that are common in speech but rarer in text.
Scatter refers to how evenly a word's familiarity is distributed across people of different vocabulary sizes. The model is less accurate for high-scatter words (words that are almost as likely to be known by people with small vocabularies as by people with large vocabularies). Technical, scientific, and specialized terms are a common example: a chemist may know titration regardless of their VCI ability, while a high VCI person unfamiliar with chemistry may not.
Such words are poor predictors of overall vocabulary size, because their probability of being known is driven by specific exposure rather than scaling with vocabulary breadth. The model assumes that word knowledge tracks vocabulary size monotonically; high-scatter words violate this assumption and therefore yield less reliable estimates.
All outputs are probabilistic estimates, not precise measurements. The model is least accurate at the extremes ends of the distribution and should not be interpreted too literally there. As with any statistical model, results are probabilistic and should be interpreted accordingly.
To read more about vocabulary and its relationship to general cognitive ability, check out the CognitiveMetrics wiki.