
Introduction
Online intelligence testing has become a popular way for users to test their cognitive ability, and most notably it is used in order to determine one’s intelligence quotient. However, such a shift towards an online paradigm has reasonably raised suspicions about the quality of the assessment, and most of this concern revolves around the validity of such tests.
With the progression of technology, there also comes the need to monetize it. As such, the transition of in-person assessments to ones done online should indeed be met with skepticism, and this is the same with many online IQ tests. However, if done properly, these online tests can actually be taken with some assurance to its validity, including those offered for free.
As such, this article will provide the opportunity for one to see how valid, online IQ tests can work for a good approximation of one’s testing ability. However, one must first cover some prerequisite information in order to understand the utility of the test and what the test measures.
Understanding Intelligence and How It Is Defined
Intelligence as a concept is defined by Oxford officially as: “the ability to acquire and apply knowledge and skills.” Such a definition is intimately related to how it is tested and defined in valid assessments. However, the definition they use is often much more specific and expanded.
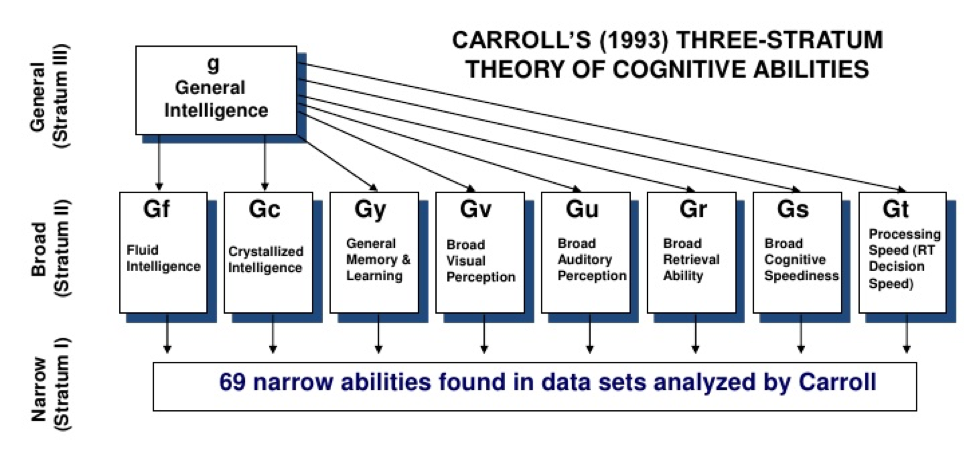
For example, the leading modern standard definition revolves around a model of intelligence, that is, most notably the Cattell–Horn–Carroll (CHC) model. Simply put, it organizes intelligence into a hierarchical model made up of various components, notably put into multiple “broad” and “narrow” categories. All of these categories are part of some larger domain, which we call general intelligence, which can be defined as one’s overall intelligence in this framework. If you are wondering what exactly the more specific categories are, that is, the broad and narrow, they have very particular definitions, but they are all easy to grasp. An example of a broad category would be fluid reasoning, which can be thought of as the capacity to solve new and novel problems through reasoning. Another broad category could be crystallized intelligence, which refers to knowledge you may have learned or picked up somewhere, like from reading the news or in school.
In any case though, CHC theory has been validated through the study of psychometrics (which will be explained later), and has found strong empirical support and validity. As such, it serves as the model for modern intelligence tests. These tests in theory should be made to capture these broad and narrow categories by creating test questions. From these test questions, they can capture a test taker’s cognitive profile by modeling their answers to various questions, either through Classical-Test-Theory or Item-Response-Theory.
Of course, as it should be noted, such a model may not fully capture the entirety of intelligence or how you may perceive it. However, CHC theory is currently the most well-validated theory due to the factors above, and has rigorous support in psychometric analysis.
As such, with such a particular definition and specific model, one may come to intuitively realize how so many online IQ tests claim to be accurate? The truth is, many are not. However, those which follow a proper methodology or science can indeed be accurate, even those done online. In the following section, we will cover some attributes of the science so you get an idea of what should actually go into making these tests.
The Science Behind Modern IQ Measurement
Now that you have a basic understanding of how intelligence is defined in this framework, it is important that you understand the basic idea of how the science works behind creating an accurate test in that framework.
To start, the most accurate IQ tests, as mentioned above, will revolve around proper item design, that is, creating test items which match the broad and narrow categories defined above. Afterwards, you of course need to have a statistical sample, or put differently, a diverse, representative group of people for you to give the test to. This sample will be assumed to then meet a threshold of accuracy in terms of representing the general population, so that when you take it, you are being compared to them without any significant bias. This is necessary, because imagine you were asked to take a math test meant for children, so that the people designing the test could get an idea on how well the test has been made so far. Obviously, that wouldn’t make much sense, since you are already an adult. A similar idea applies here.
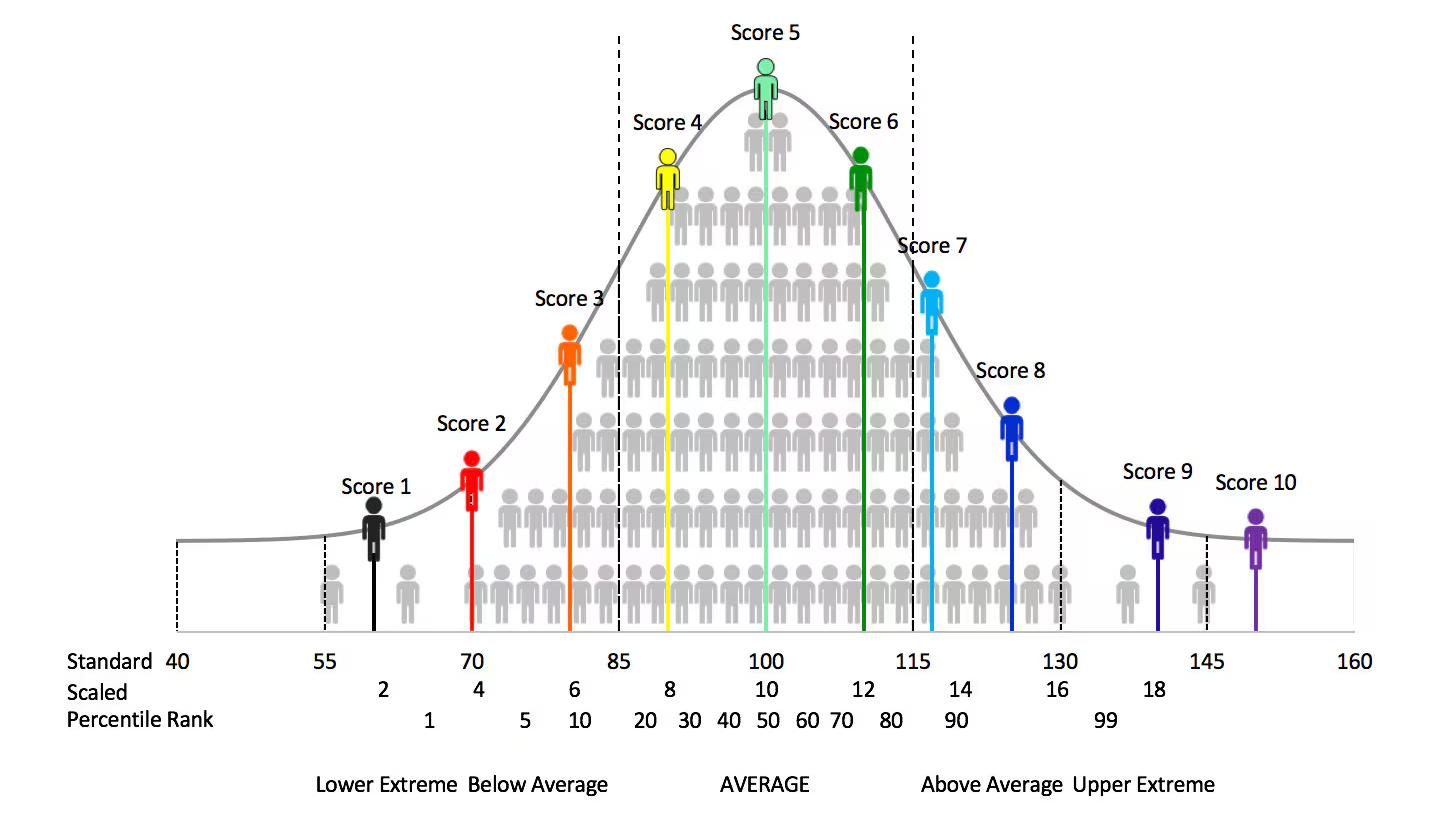
Now, earlier when we said “compared”, we meant it in the quantitative sense. You may very well know what exactly an IQ or intelligence quotient score is, for example, you might have heard somewhere that Albert Einstein’s IQ was 160. Although unverified, it is a good example of understanding what exactly the numbers mean. Einstein himself was known to be brilliant, so you might already know that a higher value might mean someone is more “intelligent”. But how exactly do you come up with these scores?
Well, they come from the data you get after a sample of people take your test. From that data, you are able to create what is known as “norms”, which is essentially used to find your score or intelligence quotient based on how well you performed on that test. In any case, the basic idea is that, from analyzing responses on your test, and removing any attempts which may have biased the sample, you are able to then create these standardized norms based on how many questions someone answered correctly. The norms are standardized in the sense that they follow a Gaussian distribution, or more intuitively a “normal” distribution, because just as how some people are taller, shorter, or just around average, IQ is expected to follow that same distribution. So, just as how some people are expected to score lower, higher, or just average, norms follow that same idea. The specific process on how it is done won’t be explained here, but they all follow statistical procedures which allow you to generate a score based on one’s performance relative to the sample.
Note:
The usage of “quotient” may point to a simple division used to compute your score, but that doesn’t reflect modern standards, which involves much more statistical methods!
The sample is defined by default to have a score with a mean of 100, that is, an IQ score of 100. The standard deviation is typically set as 15, though it can be an arbitrary number. Most people are expected to fall between +/- 1 standard deviation, that is, between 85 - 115. This empirical rule is also applicable to many other phenomena, like height, weight, test scores (in-general), and much more.
Differences Between Entertainment Tests and Research-Based Tests
Most tests claiming to be accurate probably do not fully understand the full extent of the science involved in making IQ tests. As such, one may do better with adopting a mindset that most online tests in general be perceptibly similar to just another online entertainment test. As such, the distinction between entertainment tests and research based tests are quite important. The methodology defined earlier for creating a test would fall under a research based test, and it should be assumed unless proven otherwise that most other online IQ tests do not fall under a similar category.
Additionally, most research based tests or professional tests for that matter will have a strong correlation to each other. A correlation is how strong a connection is between two categories, represented numerically from -1 to 1. A higher positive value between professional tests will indicate that they have a strong connection towards measuring intelligence. A smaller value around 0 will indicate there is no connection. So, an entertainment test is expected to have a small correlation to these research based or professionally made tests.
Question Types Commonly Used in Cognitive Assessments
Earlier when broad and narrow categories were mentioned, we talked about creating questions which were designed to model these categories. These can be thought of as “question types”, and are quite important in that they serve as building blocks to IQ tests. For example, earlier we defined fluid reasoning and crystallized intelligence. We can create one or more question types to model fluid reasoning, and one or more unique question types to model crystalized intelligence. These question type(s) modeled for one category can then be thought of as a subtest. Note that a test can have one or more subtest(s) to try to model a category.
However, you may ask which subtests are commonly used in cognitive assessments? An example of a commonly used subtest may be matrix reasoning, a particular question type meant to help measure fluid reasoning. This is a subtest which usually involves various abstract shapes or drawings, and when presented in a series or sequence, your task may be to find some underlying rule which all shapes have, and then use that underlying rule to figure out which answer choice maintains that same underlying rule. Additionally, as explained earlier, you can have various other subtests to model a category. So, put differently, matrix reasoning may be the only subtest meant to measure fluid reasoning, but it most certainly may not be the only one. You can have others alongside it, for example, figure weights, which is a subtest where you must quantitatively reason.
Another common example can be shown for the crystalized intelligence category. A common subtest which is seen on professional tests might be general knowledge. This could be thought of as a trivia test. For example, you may be asked which is the capital of a certain country. Now, you may think this could be an unfair representation of intelligence? But you should remember that a good test meant for evaluating your overall intelligence will have to include at least one other subtest to gauge the diverse structure of CHC theory, and two, the question items were presumably given to a good sample and analyzed. In other words, there have already been multiple checks in the test design which shows that this particular subtest, that is, vocabulary seems to correlate sufficiently well to where it justifies its placement in the testing structure. Another subtest could be one involving verbal reasoning. For example, you might have to reason about the difference or similarity between two known things. These could be in the form of analogies.
The validation behind these online IQ tests explained simply
So far, you have read and learned about the basic choices of proper test design, but you may ask yourself, “is there any stronger validation and connection to the seemingly abstract framework presented here?” Because sure, you can copy all the correct methods, but that doesn’t meaningfully indicate any other reason for why the analyzed outcome should imply anything important. After all, one can make a test about anything, and even though it was done similarly to the methods above, why should that be significant? For example, suppose someone made a test for how well someone can guess the correct answer based on meaningless data, data which provides no clear connection to determining the answer. And by extension, one can intutiively see that there is no such underlying theory or framework regarding how well someone can guess provided nothing important, since any connection or correlation is insignificant due to randomness.
Such a line of thinking in itself does posit an important question, and it helped lead to the development of psychometrics. Psychometrics itself can be defined as “the science of measuring mental capacities and processes”. The science part comes from the rigorous statistical methods which were developed out of necessity in tandem to the largely qualitative observations of psychology. As such, psychometrics should be thought of as a subset of psychology, but one with very strong statistical and mathematical methods to give it rigor.
Now that the field of psychometrics has been introduced, one can cover how someone might exactly use that to support the validity of such tests, and the theory itself. The basic idea explained earlier involved the introduction of a hierarchical framework with certain categories or structures, all under the concept of overall intelligence, or general intelligence. We call the framework of CHC as a factor structure. The reason why these structures have been accepted is that they arise out of certain techniques, such as factor analysis. What exactly might this be?
The easiest way of explaining this idea is to first start with an assumption, and logically similar to proof techniques (though not as rigorous in this context), find a contradiction. Let us first assume that the idea of general intelligence in itself is a meaningless theory that implies nothing. Now, let us try to validate whether a test is sufficient under such a model. Factor analysis allows us to analyze item responses from a matrix of correlated data, and use complex statistical techniques to do so. Specifically, from test responses, or other test data, one can apply a series of methods to summarize the factors responsible for such responses. These factors could be described as “latent variables”, factors which are hidden behind the testing structure. To put it more clearly, we can think of “athleticism” being a latent factor behind the performance of athletes on various Olympic tests. Additionally, along with the extraction of these factors, we also get a strength of which factor contributes the most to the data we extracted. From our analysis, we get a clear view that one factor is the strongest in dictating the variance or spread behind all the data analyzed. Put simply, one factor presented itself as indubitably the strongest share for why the data was spread out a certain way.
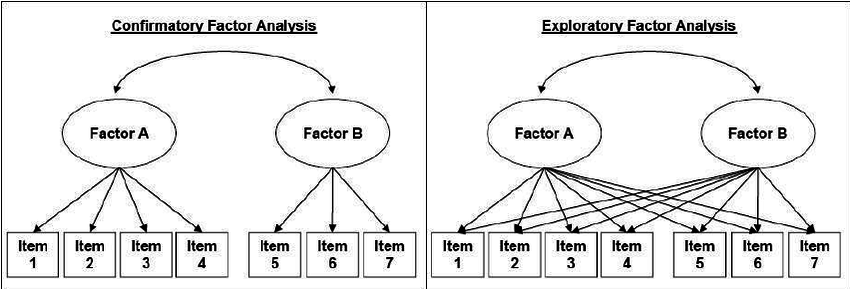
Now, earlier we made the assumption that general intelligence has no bearing or value as a concept. It was assumed to be meaningless, so, in this context, ask yourself this, if it is not general intelligence, which factor might it have been instead? Maybe it has to do with how many years of education you have? Or maybe how much you read? How can we really be sure? We can’t, not unless we can confirm it. Fortunately, one can confirm it, and this is done through Confirmatory Factor Analysis! What we did earlier was Exploratory Factor Analysis, when we extracted the factors responsible for why our test data turned out a certain way. However, naturally with the hidden and unknown nature of the factors extracted from EFA, it necessitates some other form of analysis to confirm whatever speculations for what that framework or factor structure might be, which CFA is used for.
So, going back, we assumed that maybe a different model is the explanation for that factor. So, let’s say we ran with the idea it must be how much you read. More specifically, let's say that one particular grouping of question types has to do with one particular factor, and the other grouping of question types has to do with some other factor. We keep doing this in a similar fashion to questions we think could correlate the best to our supposed explanation. In doing so, we essentially create some unique theoretical structure which will generate some intercorrelation matrix.
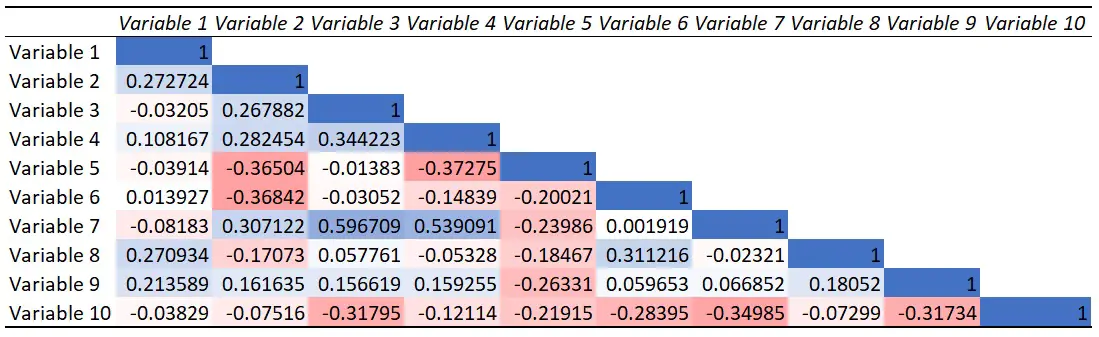
After building this particular model, we run an analysis, and we find that unfortunately, we find that the hypothesized structure here has no true relationship to the intercorrelation matrix we used for the EFA. In that case, we keep rerunning the analysis with other rules or theories, but we find there is no model which can come close to serving as an explanation for that factor. However, we go back to our earlier assumption. Is it really true that general intelligence, with constructs defined from CHC theory, will also follow this pattern of having no connection? For example, general intelligence sits at the top, and for this test, we assume two broad factors of fluid reasoning and crystallized intelligence are influenced by it. Then, we group the question types. So, when we go to check, we find that general intelligence actually does happen to be the main factor which consistently emerges the strongest for our configuration. We repeat this process on multiple tests and analyses and find the same pattern.
Consequently, the validation of CHC-theory and IQ tests follow a similar process which fits more consistently and better than alternative explanations or models (of course, it is still possible a "better" model can show up, but nothing has as of yet in terms of matching the consistency and broadness). Clearly, it is not by coincidence but by a rigorous and consistent showing which supports the existence of this framework. As such, this entire process is really one that revolves around supporting an idea known as construct validity. In the end, the entire intuition revolves around the fact that cognitive abilities seem to correlate in some meaningful, positive correlation. Such an observation is also known as the “positive manifold”. These patterns, when analyzed, reveal a dominant general factor and factor structure which aligns the best to CHC theory, and no other model comes as close to fitting the data better than it.
Note:
Essentially, what we are doing in EFA is starting from an observed correlation matrix derived from our own test data (e.g., correlations between different subtests or item types) and fitting a factor model that can reproduce that matrix. The key motivator is the idea of a positive manifold, which is the idea that many cognitive measures tend to correlate positively with one another, which in turn suggests a general factor like g may exist. An intuitive way to understand what this “positive manifold” means is the athleticism analogy: someone who is clearly good at calisthenics should perform well on calisthenics-related exercises, and they will also probably perform well on some weightlifting exercises. Altogether, it makes sense to posit that performance across different but related physical tasks tends to “move” together, which makes it logical to model them with an underlying latent trait such as athleticism. Now, as for CFA, it is done by specifying a hypothesized factor structure. That model, in turn, creates an implied correlation matrix which we can compare to the observed data. Which, in the context of valid IQ tests, tends to compare well. Now, if the idea of an emergent factor is still cloudy, we can still go back to our trusty athleticism analogy. For example, say a computer observed 100 athletes across many different exercises/tasks. It found those who did well at calisthenics tend to again, do well at weightlifting. So, it groups these together and discovers a latent construct like athleticism which is linked to both, however, since it was looking for any pattern, it also finds that many tasks overlap across groups (see image above, this part is conceptually what EFA is). Logically, this still makes sense, as both must be correlated to each other, and then both be correlated to athleticism, but the finding that other relationships may emerge is a problem since we want a specific theory. In any case, we still suspect that athleticism really only has two distinct sub-groups in this context regardless of what other relations were found, such as bodyweight strength, and the other being the ability to lift an external weight. Going back to the computer, we asked it to confirm if this structure is valid, but we also made sure to tell it which relationships should exist (the two subgroups). It finds that our structure, despite being more specific, fits well, because using our theory, we can reproduce the correlation pattern that closely resembles the real-world data observed and used for the EFA (this part is the CFA). This entire process is conceptually similar to the validation of well-made IQ tests.
Common Myths About Free Intelligence Testing
There are, of course, several misconceptions around these free tests. However, they reasonably stem due to the prevalence of other misleading online tests which make no effort in properly adhering to the science explained above. However, some may use the prevalence of these misleading tests to completely invalidate the entire concept of intelligence testing. This is done rather unfairly, since the model defined meets many empirical and predictive validity checks, showing that it is a tangible framework. If it is the case that tests which do not meet this framework are made, that in itself is not a sufficient argument to conclude that intelligence testing as a whole is fake.
Another myth may be that all online IQ tests are inaccurate relative to the usage of tests done in person. This is another point which is attributed to the prevalence of misleading online IQ tests, which can be accounted for due to the same argument above, that is, a large misrepresentative batch does not invalidate the science for the minority of actually representative batches. However, even when the misleading online IQ tests are removed from the argument, this same argument may be made. Does one not need to have to take a test in-person in order to get an idea of one’s intelligence quotient? The answer is not necessarily, so long as certain conditions are met. For example, if one does not ruin the test’s integrity by cheating, and so long as they follow standardized protocols which everyone else in the online sample does, the truth is, there shouldn’t be any significant reason for why the framework cannot be captured. After all, there is a reason why many educators have moved paper tests to tests done online. The difference is negligible so long as reasonable conditions are met. In any case, however, tests proctored by a professional and evaluated by one personally are the best. But, the idea to invalidate all online IQ tests is not a very strong one for most cases.
There are a few other notable misconceptions, but most revolve around whether or not IQ is representative of intelligence and if it is even accurate. The answer to most of those, falls under the interpretation and acceptance of the model above, and so other definitions of intelligence will have to naturally disagree. However, in terms of the broad, official definition of intelligence defined earlier, the theory behind which IQ tests follow has demonstrably been the best and most well researched.
Ethical Considerations in Testing
The ethics of IQ are indeed an important consideration, especially in the context of test-design and administration. However, note that these considerations are often already built into the test itself. For example, the goal of fair testing is strongly sought after already to begin with, and as such, already accounted for. This is done again, through the selection of a proper sample. Additionally, in terms of administration, the test will make note on who to give the test to, for example, tests will explicitly state in their directions to not give the test to anyone who they might think may not be properly represented. For example, an English based test is never given to anyone who is not a native English or strong English speaker, this is done based on test directions by design. This same principle is done to properly make online IQ tests.
When an IQ Test Can Be Genuinely Useful
Now that you know the science behind IQ tests, you may ask yourself what is the point in this creation? Originally though, one should know that the first IQ tests were meant to help identify students who needed special educational support. This is still done today as well, and can be done in multiple related situations.
Most of the uses revolve around understanding one’s cognitive profile. From that understanding, a specific tailoring revolving around that cognitive profile can be done based on that person’s strengths and weaknesses. Keep in mind that the model of these tests encompasses multiple categories, all of which have been validated. We have only introduced a glimpse of these categories, but it is important to keep in mind there are many more of these categories, and that they all have a proper reason for being there. As such, there is a great degree of specificity and detailed value in these tests. For example, these tests (specifically done by a professional) can be used to diagnose dyscalculia, or other conditions like non-verbal learning disorder. This is because these IQ tests allow the professionals to observe the behavior of the person taking the test, and write specific notes about how they behave. Additionally, these tests in general can also be used to help a person understand their own strengths and weaknesses objectively.
Conclusion
Online IQ tests are often perceived through a lens of entertainment or one with skepticism. However, when these tests are properly made, they have a tangible purpose and are not invalid due to most criticisms applicable only to misleading tests. Platforms which take into consideration the full scope of the information presented earlier can provide a sufficient approximation, can provide a test taker with useful information in more ways than not. If you are further interested in reading, you should also check out the wiki.

Comments
Sign in to leave a comment.
No comments yet. Be the first to comment!