CAIT has a successor: CORE, a more comprehensive and accurate battery for measuring IQ.
This test is temporarily unavailable. You can take CORE for free below. Your CAIT scores and dashboard remain accessible, but for the most accurate experience, we recommend taking CORE.
Welcome to the Comprehensive Adult Intelligence Test (CAIT) by u/EqusB.
The aim of project CAIT is to provide a free resource for estimating a full scale IQ (FSIQ) score similar to the WAIS for adults interested in cognitive testing. The CAIT is designed for individuals over the age of 16.
The CAIT is inspired by and formatted to resemble the Wechsler Adult Intelligence Scale (WAIS). Overall, the goal is to provide a similar but streamlined experience that can estimate FSIQ in a timely manner.
Estimating FSIQ across a diverse range of test batteries is the best way to estimate the g factor, or general factor of intelligence. Most online IQ tests concentrate on measuring a single factor. The CAIT is designed to provide a more comprehensive view of general intelligence by testing multiple factors.
The CAIT is an open-ended project that will be updated over time to make it more accurate and more comprehensive. If you have taken the WAIS professionally and decide to take the CAIT, please submit your scores to help improve this test.
No outside resources are allowed at any point during this test. Pencils, paper, calculator, Google, etc., are NOT ALLOWED. The use of any outside resources invalidates your test result.
You can view your subtest and index scores in the dashboard after taking the relevant tests. You can also access the score calculator at the following link: CAIT Score Calculator.
Note: The CAIT is not a substitute for a professional IQ test. Scores obtained using the CAIT, if taken correctly, are designed to give an accurate estimation of FSIQ. However, the CAIT is not a diagnostic tool and cannot be used in any capacity other than as an informative tool. Individuals seeking a diagnosis or comprehensive psychological report should be tested by a professional.
The CAIT is designed for native English speakers and adults over the age of 16. Non-native English speakers cannot receive an accurate Verbal Comprehension Index. Individuals under the age of 16 cannot receive an accurate IQ score.
Out of the total 1692 attempts, the sample had to be filtered according to various criteria to ensure that the influence of invalid factors would be minimized. Only the following attempts were considered: first attempts, both VCI and PRI attempted, non-floor attempts, attempts from native English-speaking countries (US, CA, UK, IE, AU, NZ). After narrowing down this sample, we are left with 449 valid attempts.
| V | GK | VP | FW | BD | |
|---|---|---|---|---|---|
| V | 1.000 | 0.672 | 0.305 | 0.283 | 0.212 |
| GK | 0.672 | 1.000 | 0.320 | 0.393 | 0.212 |
| VP | 0.305 | 0.320 | 1.000 | 0.649 | 0.623 |
| FW | 0.283 | 0.393 | 0.649 | 1.000 | 0.501 |
| BD | 0.212 | 0.212 | 0.623 | 0.501 | 1.000 |
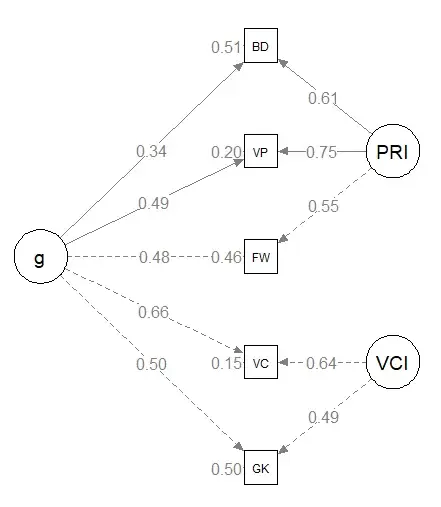
g-Loadings
| Measure | Mean | SD | Reliability | g-Loading * |
|---|---|---|---|---|
| GAI | 124.79 | 15.98 | 0.923 | 0.852 |
| VCI | 125.06 | 15.63 | 0.904 | 0.804 |
| PRI | 119.76 | 17.54 | 0.890 | 0.689 |
| VSI | 121.66 | 17.04 | 0.879 | 0.636 |
| V (SS) | 14.14 | 2.66 † | 0.795 | 0.825 |
| GK (SS) | 15.12 | 3.65 | 0.870 | 0.704 |
| VP (SS) | 13.93 | 3.46 | 0.826 | 0.648 |
| FW (SS) | 13.38 | 3.68 | 0.816 | 0.620 |
| BD (SS) | 14.07 | 3.52 | 0.835 | 0.504 |
* This sample has a mean of 124.79, much higher than the average person. In order to ensure an
accurate measure of this test's g-loading, it must be adjusted for SLODR (Spearman's law of
diminishing returns). For example, while the GAI g-loading was calculated at 0.716 for this
sample, the corrected g-loading returns 0.852.
† Due to the standard deviation of Vocabulary being below 3, it was corrected for range
restriction.
Looking at the g-loadings of various subtests, some things stand out. Vocabulary being the highest
subtest makes sense, being based on the already well-established SAT-V.
Let's compare the rest of the subtests to the WAIS-IV and WISC-V:
| CAIT | WAIS | WISC | |
|---|---|---|---|
| IN (GK) | 0.704 | 0.648 | 0.721 |
| VP | 0.648 | 0.679 | 0.648 |
| FW | 0.620 | 0.715 | 0.530 |
| BD | 0.504 | 0.687 | 0.639 |
| Average | 0.619 | 0.682 | 0.635 |
As shown, the CAIT seems to stand with the professional counterparts it was designed to estimate. Why CAIT's Block Design is so low is up to speculation, but it may be due to format differences. The CAIT BD format is based on the multiple-choice version of WISC BD for the physically-impaired that does not require blocks. However, the WISC and WAIS both make use of physical blocks.
The sample that was used to calculate the g-loadings is of inferior quality compared to the WISC and WAIS. Unfortunately, due to the nature of online testing, it is difficult to control for all external factors that may have affected this sample, such as cheating, distractions, interruptions, etc. Nonetheless, this doesn't invalidate the g-loadings calculated above.
Core Subtests:
Core Subtests:
Supplemental Subtests:
Core Subtests:
